
Concept-centric Representation, Learning, Reasoning, and Interaction (CReLeRI)PI: Zhiting Hu (UCSD) Co-PIs: Jaime Ruiz (UF), Daisy Wang (UF), Eric Xing (CMU), Jun-Yan Zhu (CMU)
Funding Organization:
Defense Advanced Research Projects Agency
Funding Amount:
$4,394,789
Funding Period:
202307-202607
We propose the new perspective of Concept-centric Representation, Learning, Reasoning, and Interaction (CReLeRI) that addresses the above fundamental challenges with a suit of methodological innovations.
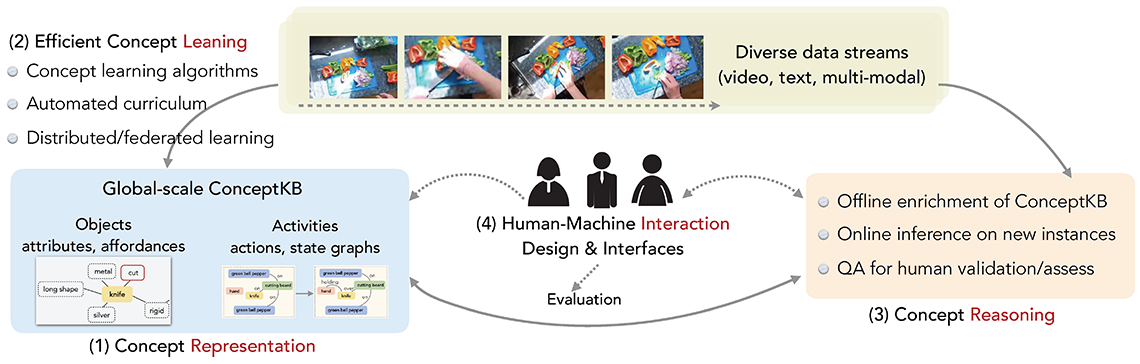
As shown in the figure, we propose four key Research Aims led by the PI and co-PIs who are world experts in their respective domains. The team is well-positioned to deliver each of the research aims by developing innovative techniques:
- Aim 1: Symbolic Compositional Representation of Concepts. We devise the new symbolic representation schemes for the complex concepts of objects and activities that naturally support easy composition, simple-to-complex incremental learning, and uncertainty/ambiguity handling. Based on the representation schemes, we will construct a global-scale Concept Knowledge Base (ConceptKB) that scalably stores and manages the massive concept ontology learned from diverse data streams (Aim 2) and efficiently
supports rich reasoning and inferences to answer complex concept-centric questions (Aim 3) as well as interactions with human analysts (Aim 4). Specifically, for object concepts, we model both the object attributes (e.g., color) and affordances (e.g., capabilities, utilities). An object concept is represented as a composition of the relevant primitive attributes and affordances, resulting in a graph structure that links the object node to the respective attribute/affordance nodes associated with semantic embedding vectors.
The compositionality allows us to represent numerous objects where different objects could share common attributes and affordances. This both makes it efficient to acquire new concepts without the need of a large amount of data, and also facilitates curriculum
learning in which the acquisition of complex concepts can benefit from the simpler concepts learned earlier by reusing the knowledge. The activity concept representation shares the same advantages of compositionality. Each activity consists of a sequence of primitive actions as well as state graphs that capture the trajectory of change in object states. With multiple agents learning concepts on diverse data streams in parallel, it is crucial to handle the uncertainty, ambiguity, and even contradictory information in the learned knowledge. The object/activity representations are augmented with weights on the graph structures and action orders to capture the uncertainties and facilitate downstream probabilistic modeling and reasoning as well as human interaction. The uncertainty weights will in turn evolve as more data is observed, new knowledge is acquired, and human feedback or
intervention is provided. - Aim 2: Efficient Concept Learning at Scale. We intend to develop principled learning algorithms that acquire massive object/activity concepts from diverse data streams in an efficient, distributed, incremental, and never-ending manner. To learn the object concepts, differing from the previous approaches that are based on the closed-world assumption (e.g., by requiring a predefined set of attributes) and/or rely on massive training data, we develop a new structured neural approach that automatically discovers new attribute/affordance notions necessary for describing the observed objects. In particular, we learn the binding of objects to the appropriate attributes/affordances with a “bottleneck” architecture that uses the attribute/affordance representations as the surrogate representation of an object. The representation is then used and optimized for the model to reconstruct/explain the observed data. We will devise an efficient gradient-based sampling method for fast selection and automated expansion of the attribute/affordance nodes. As an important component of the learning, we will develop a new advanced concept-based generative modeling technique. Activity concept learning is closely related to object acquisition, as we will impose consistency constraints (e.g., between the object affordances and the activity state graphs). Besides, we will derive and integrate other rich experience/supervision signals to learn activities, such as the object spatio-temporal patterns in the video frames, the visual-textual paired data, and the previously learned activity concepts. The whole concept acquisition process is charted into a curriculum that is automatically optimized based on the learning progress and data difficulty. Notably, we will formulate the concept learning from rich experience, as well as the curriculum optimization, jointly based on our previous standardized machine learning formalism. This will result in a principled framework that automatically coordinates and balances the
concept learning and curriculum adjustment.Scaling up concept acquisition from large, dynamic, multi-model, and heterogeneous data streams, and scaling out of traditional silo-ed computing infrastructure represents a bottleneck of practical decision-making systems based on concept-centric learning. We will design new distributed and federated learning algorithms and systems to deal with challenges in real-world applications that involve large volume, heterogeneity, and distribution shift of data streams (e.g., social user photos, and surveillance videos) and decentralized sensory and computing platforms, e.g., drones and edge devices. Our algorithm allows agents to learn individual concepts to fully respect their expertise. And the agents’ learned concepts are then aggregated to complement each other in ConceptKB through the developed uncertainty quantification and consistency aggregation mechanism. We also propose
to handle strategic relationships between agents, e.g., cooperative or adversarial agents in distributed environments. These situations pose additional challenges but also opportunities for scalability, generalizability, and trustworthiness of the methods we propose to develop for concept acquisition. - Aim 3: Reasoning with the Learned ConceptKB. The research aim consists of two parts: 1) model-based reasoning based on the learned ConceptKB constructed from Aim 1 and Aim 2 (TA1); and 2) human-assisted validation and assessment of the knowledge in
ConceptKB, which communicates with human-machine interaction interfaces and designs in Aim 4 (TA2). For the first part of model-based off-line and real-time reasoning over entities, affordances, and activities in ConceptKB, we will leverage our prior work in
knowledge graph link prediction [92, 91, 85, 8] to adapt and advance the SOTA model on few-shot link prediction by leveraging both symbolic knowledge, including rules, constraints and graph patterns, and neural models based on GNN and language models. Over 3 years and the first 2 phases, we will explore few-shot link prediction from simple entities and attributes, to composition entities and affordances, to a sequence of events and activities. Further, we propose a ConceptLinking service to link the knowledge
elements in ConceptKB to those in a large commonsense KB, so that we can enrich the ConceptKB with additional external knowledge. Finally, we propose to extend a new knowledge harvesting paradigm to automatically extract symbolic knowledge relevant to
the knowledge elements in ConceptKB from large language models. For the second part of human-assisted validation and diagnostics, we will leverage our prior work on narrative generation, and question answering from knowledge graphs. We propose to assess the quality of knowledge elements in a ConceptKB based on uncertainty and consistency measures, where uncertainty can be computed from linking and aggregating over multi-agent input and consistency can be computed based on other knowledge elements in ConceptKB, including learned rules, constraints, as well as external knowledge such as language model through natural language entailment. With the uncertainty and consistency measures over knowledge elements, we can then generate and rank the knowledge subgraphs in ConceptKB that is most uncertain and inconsistent for human validation. In a later phase, we will also look to optimize the ranking function with the value of information, because not all knowledge elements in ConceptKB are equally important. Given a set of predefined question types and a ranked list of knowledge elements in ConceptKB, we extend the existing question generation model and framework
to generate natural language questions for human validation. Extending the graph2text models, we propose to advance the current question answering algorithms to answer complex questions by subgraph retrieval and narrative generation from sub-graphs. We
understand the potential challenges in these proposed methods, and we will also explore a mixture of question answering modality including natural language, structured tables and sub-graphs. - Aim 4: Human-Machine Interaction Design and Interfaces. In order to design effective visual analytical tools for the true human-in-the-loop exploration of complex data, it is essential to consider the human understanding of models, human interactions with the system, and how the models influence analysis outcomes and behaviors. As such, the research involves iterative prototyping and evaluations with human participants to assess how different algorithmic and visualization designs influence analysis outcomes, analysis behaviors, and understanding of the output. We will develop a multimedia interface that enables direct manipulation of ConceptKB. In addition, the research will develop novel visualizations of our underlying semantic representation to help end users understand the system’s current understanding. To reduce the time and effort required by users to provide verification and refinement of concepts, we will develop novel techniques to identify patterns in users’ history of corrective feedback in order to communicate the outcomes created by their feedback. Lastly, the research’s strong focus on user-centered design
ensures the user interface meets both user and program requirements through iterative design and continuous user study evaluations.